先週の木曜日に横浜でJTF翻訳祭が開催されました。去年に引き続き、日本知的財産翻訳協会(NIPTA)の「NIPTA特許機械翻訳研究会」の研究内容の報告をさせていただきました。お越しいただきましたみなさま、どうもありがとうございました。
<目次>
発表内容
株式会社翻訳センターの渡部さんが、ニューラル機械翻訳の定点観測として、同じ和文明細書を用いて、去年と今年の日英翻訳結果を発表しました。翻訳結果は変化しており、よくなる場合と悪くなる場合、またほとんど変わらない場合、全く変わらない場合などに分類されました。分野により評価が異なりました。またエンジンにより傾向も異なりました。そして、ニューラル機械翻訳の出力は、現時点においても新規の特許出願に用いる翻訳にはそのままでは使えないと結論付けました。
一般財団法人日本特許情報機構の清藤弘晃さんは、「特許ライティングマニュアル」に基づき原文修正をした場合の訳文の品質向上の傾向を評価しました。原文を短くして主語と目的語、述語を明記すれば訳文の出力が向上することがわかりました。これは当たり前かもしれませんが、機械翻訳と付き合う上では重要なポイントです。ただ、冗長表現と思われる個所を書き直しても訳文に影響を与えない場合もあることも報告されました。

私は、このような結果を踏まえて、どの程度の原文修正が実務者にとって適当なのか、例を示しました。原文修正をすれば訳文の出力がよくなることはわかるのですが、原文修正に時間をかけすぎても意味がありません。
翻訳者が時間をかけるべきことは、原文修正ではなく訳文修正です。
私は、「訳文修正がしやすいように」もしくは「思い描いた訳文を作るためのパーツを得やすいように」原文を修正するにとどめるのがよいと思います。なので、出力された訳文の構文が崩れるような場合や訳抜けがひどい場合などに、原文を少し修正するだけで出力される訳文がよくなるのであれば原文を修正すればよいと思います。
そのための方法を以下、紹介します。一文ずつ翻訳をする手法をイメージしています。ニューラル機械翻訳の支援ツール「GreenT」のようなツールを使わなくても、一般的な翻訳支援ツール(Trados、Memsource、memoQなど)に機械翻訳を組み込んだ環境であれば、原文を修正して同じような結果が得られます。
プリエディット(原文修正)の方法
以下のスライドを用いて、原文修正には2種類あると説明しました。人間の判断がいらないような修正は一括置換などを用いて手軽に修正できます。マクロを作って一括処理をしてもいいと思います。

翻訳祭では、上記のような文書全体の一括処理ではなく、1文ずつ訳す場合の修正例をいくつか紹介しました。
私は、プリエディットでは「1.主語を特定しやすい文章を作る」と「2.係り受けがわかりやすい文章を作る」の2点が肝だと思っています。そして、編集後の原文が「日本語として不自然であっても気にしない」ことも重要だと思っています。これは、8月のTCシンポジウムでの発表でもお伝えした通りです。

コツ3では、TCシンポジウムでの川村インターナショナルさんの発表内容※を特許の日英翻訳で利用した成果を紹介しました。
※:森口功造、中安裕志、星井智(2019) 「日英機械翻訳前のプリエディット~そのポイントとポストエディットによる補完~」 テクニカルコミュニケーションシンポジウム2019論文集, pp. 66-73
以下、具体例を紹介します。出力された訳文の評価はしません。構文の変化を確認するための例文です。
コツ1
無生物主語構文を作ることを念頭に置いて原文を修正すると、文章構造を意図したように修正できることがあります。原文をきれいに修正しなくても以下のように一部分だけ修正しても結果が得られる場合があります。

コツ2
主語を入力します。正しい主語を書いてもいいのですが、「それ」と仮の主語を原文に追記し、訳文で出てきた「it」を正しい訳語に修正すればよいと思います。構文を変えることを目的として原文を修正しているからです。

コツ3
川村インターナショナルさんのアイディアを拝借してプリエディットの効果を評価をしました。句点を挿入するだけで、こんなに変わります。中途半端な接続詞であっても、翻訳エンジンがそれなりの文章をひねり出します。当日は同様の例をいくつか紹介しました。

この手法が優れている理由が2つあります。
1つ目は、セグメントを分割せずに文章を分割できるということです。当研究会の去年の発表でも紹介したとおり、セグメントを分割して短いフレーズにすると訳しやすい場合があることはわかっています。しかし、この手法の場合には、CATツールを利用していると、原文のセグメントの分割や再結合という作業が発生してしまうので少し面倒でした。
ところが、この「句点挿入」の手法では、CATツールの原文のセグメントを分割せずに文章の意味だけを分割できるので便利なのです。
2つ目は、文として正確な表現でなくてもニューラル機械翻訳が訳文を出力できるという癖を上手に利用していることです。実務者にとって原文修正は手間なので、その手数を減らす手法である点が優れています。
実は、和文だけでなく英文でもピリオドを挿入することで同様の効果があることがわかっています。いろいろな場面でお試しください。
コツ4
研究会の化学分野のグループメンバーが使っている方法です。化合物名が長い場合、簡単な文章であっても文章が壊れる可能性が高まります。この化合物名を「化合物A」と置き換えると、係り受けのわかりやすい原文になり、情報を正確に反映したすっきりとした訳文が出力されます。このような工夫も面白いですね。

仕組みや工夫が必要
いずれにしても、ニューラル機械翻訳を翻訳に使う場合には使い方の工夫が必要です。
「ニューラル機械翻訳を使うから翻訳が簡単になり安く仕上がる」なんて安易な考えでコストダウンを要求するクライアントがあるようですが、これは大きな勘違いです。
要求する品質によっては、最初から人手翻訳でしたほうが良い場合もあります。
お客様とお話をしていると、特許事務所ごとに目指している品質が異なると感じます。「ささいなミスは中間処理で修正をすればいい」という方針のもと、細かなチェックを省いている事務所があります。それに対して、数字や用語を一つ一つ丁寧に色を付けて(PC上での着色、または印刷した原文と訳文とを突き合わせて)時間をかけて確認しているような事務所もあります。
このような差は、企業の知財部同士でもありますし、翻訳会社同士でも翻訳者同士でもあります。要は、翻訳会社や翻訳者はクライアントが求める訳文を提出する必要があるため、取引のあるクライアントにより日頃のチェック項目も訳文の文体も異なると思ってよいと思います。
品質といっても、会話の相手と同じ意味で使っていない可能性があると思うほうがよいと思います。このことを、過去10年間、色deチェックというチェックツールの販売やユーザーサポートを通じて様々なお客様と意見交換をしてきて感じています。また、最近活発になっている「翻訳品質とは何か?」の議論を見聞きしても、同じように感じます。
以前の記事「翻訳を評価する「視点」の違いについて」で用いたイメージ図を、特許翻訳用に以下のように作りかえました。品質を考えるときに考慮する情報の範囲を示しています。
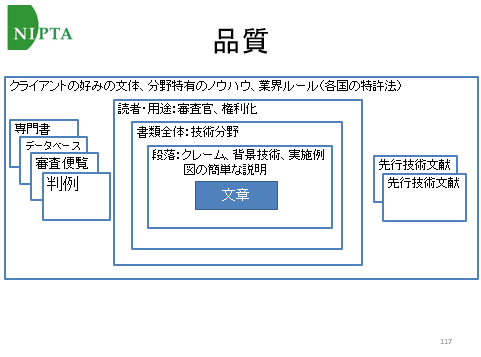
翻訳者は、翻訳対象の文の意味を理解するだけでなく、その文が書かれている段落の役割、前の文との関係、図面の情報、表の情報、特許明細書の書き方のルールなどを考慮して訳文を作ります。
さらに特許事務所のインハウス翻訳者だと、判例に基づいて翻訳表現を選んだり、中間処理で特定の審査官の審査の癖を考慮して表現を選ぶ場合があります。それぞれの翻訳者にとって目指す品質や答えがあり、それに近づけるように努力をしています。
一方で、機械翻訳では一般的には1文のテキスト情報だけから訳文を出力しています。当然図面の情報も考慮していないし、特許法や審査便覧、判例なども考慮していません。
その出力された訳文を目指す訳文に近づける作業がポストエディットです。この「出力された訳文」と「目指す訳文」の差が大きい場合は編集作業が大きくなるため、機械翻訳を使うことによりむしろコストが増大します。

なので、ニューラル機械翻訳の導入には、出力された訳文をどのように利用するのか、文書のどの部分で使うのか、どの品質での訳文を求めるのか、など決めたうえで、スキームを工夫していかないとコストがかかるだけの場合もあります。
今回のセッションでは、このようなニューラル機械翻訳を利用するスキームがテーマではなかったので、このスライドの説明にはあまり時間をかけませんでした。ここでは、仕組みや工夫が不可欠であることをお伝えしようと思っていました。
プリエディットとポストエディットを別の人が担当する?
ニューラル機械翻訳の活用方法を検討した結果、「プリエディット」担当者と「ポストエディット」担当者が分かれることがあるようです。セミナーで「プリエディットとポストエディットを別の人が担当することは効果的か」というような内容の質問をいただきました。
これは訳文の用途や目指す品質で答えが異なると思います。また、プリエディットの作業内容とポストエディットの作業内容により回答が異なるでしょう。なので、セミナーでもお断りをしたように、私が想定する作業内容(上記で紹介したテクニック)だと担当者を分けることが効果的という印象を受けません。
むしろ、翻訳に関わる人が増えると人件費が増えるので、その分のコストを上回るだけの生産性や品質の向上がない限り、費用対効果がでないと思います。
原文の修正に関して言えば、原文の内容を読み込まないと修正が必要とされる箇所を特定できないし修正自体の正誤の判断ができません。この内容を読み込む努力(脳みそのエネルギー)がもったいないと感じます。ポストエディットの担当者はどちらにしても原文を丁寧に読むわけですから、その人がプリエディットまでしたほうが効率的だと感じます。
よくよく考えると、私は上書き翻訳やGreenTを使った翻訳でプリエディットに相当する作業をしています。たとえば、用語集を作成する過程で見つけた原文の誤記や表現の揺れを修正します。
用語集の作成工程では主要な言葉の訳語を特定するために原文を丁寧に読むので、後工程で翻訳をする際に内容が頭に入っていて翻訳効率が上がります。このように、翻訳前の作業が訳文作成に役立つのだから、ポストエディット担当者が原文修正をするほうが効率がよいと思います。
目的に対してスキームを組んでいくので様々なアプローチがあってよいと思います。誰がどのような作業を担当したとしても、定められたコストと納期で、必要な翻訳品質の訳文を提出できればそれが正解だと思います。
ニューラル機械翻訳では、これまでの翻訳作業のプロセスではなかった作業が必要になります。相応の工夫が必要だと思います。
まとめ
去年のNIPTAの発表でもしたように、ニューラル機械翻訳を使って出力を修正する場合には、原文を理解する力と訳文の言語のライティング力が必要です。ニューラル機械翻訳はこれらの専門的な力を補うものではありません。
今後もニューラル機械翻訳の活用について研究を進め、お客様にとっても翻訳者にとってもフェアな仕組みを作る必要があると思います。