Wordで動く翻訳チェックソフト「色deチェック」の使い方の紹介です。前回の「英数字が合っているのに誤判定になる例と対処方法(その1)」の続きです。誤判定が出る理由と設定方法を紹介します。
(2020年12月12日) 動画をアップしました。 英数字が合っているのに誤判定になる例と対処方法(動画)
<目次>
振り返り
まずは、前回のまとめから。
チェック結果が思うようにいかないケースがありました。ユーザーさんからの質問を元に例を作成しました。実は、すべて合っているのですが、こんなに黄色(色deチェックでは、誤記の可能性がある箇所が黄色になります)がついてしまいます。
(チェック前)
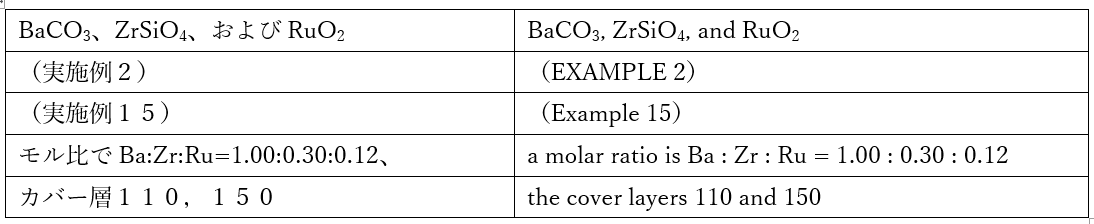
(チェック後)
前回の記事で、[英数字記号1]タブの設定方法を紹介しました。その結果、黄色の個所が減りましてこのようになりました。
(チェック後)
この記事では、上記の黄色になっている誤判定がなくなるような設定方法を紹介します。うまくいくと、以下のように黄色がなくなります。
[英数字記号2]タブの設定
前回の記事で[英数字記号2]タブの2か所の設定を変更することを提案しました。それぞれの役割を再度確認してみます。
誤判定が多くなっているときの設定は以下のようになっています。
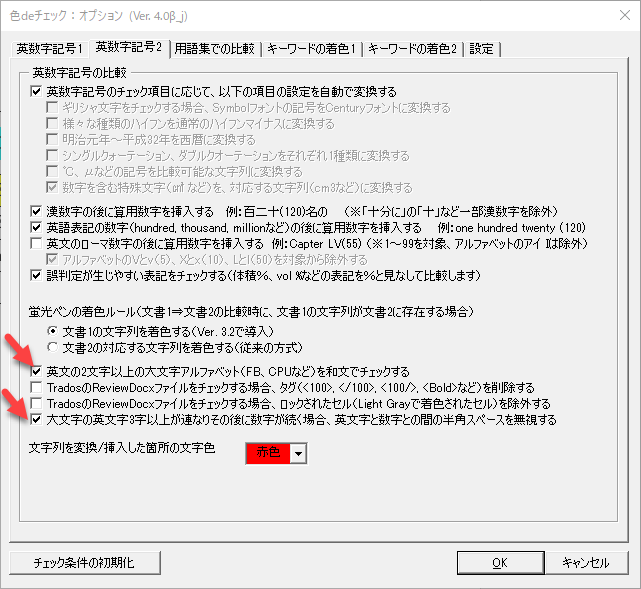
ここはそれぞれ、英文中の大文字アルファベットのチェックに関係した項目です。
この項目の役割がわかると、黄色になっている箇所が誤判定であると自信をもって判定できるので黄色になっていても気にならなくなります。
もしくは、誤判定が多く出る文書に対しては設定をオフにして、不要な誤判定を回避してもいいでしょう。
英文の2文字以上の大文字アルファベットを和文でチェックする
チェック結果
以下の設定になっているとします。
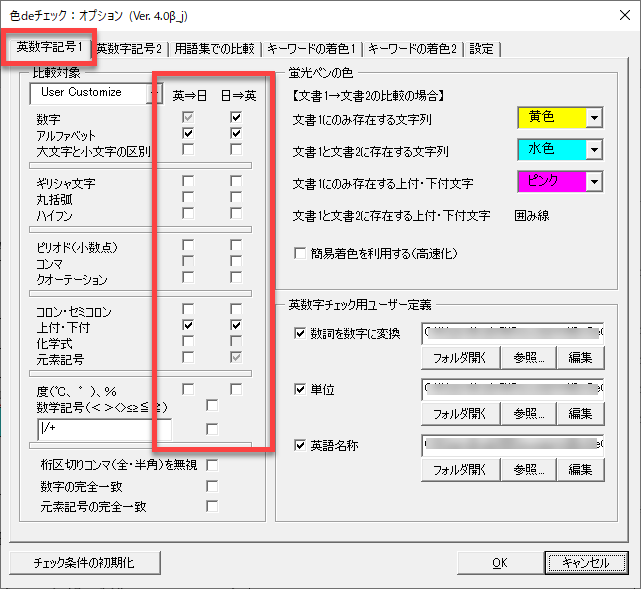
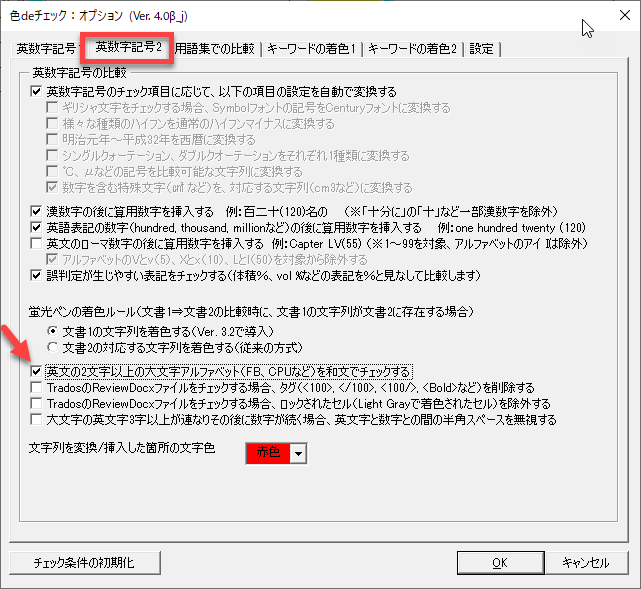
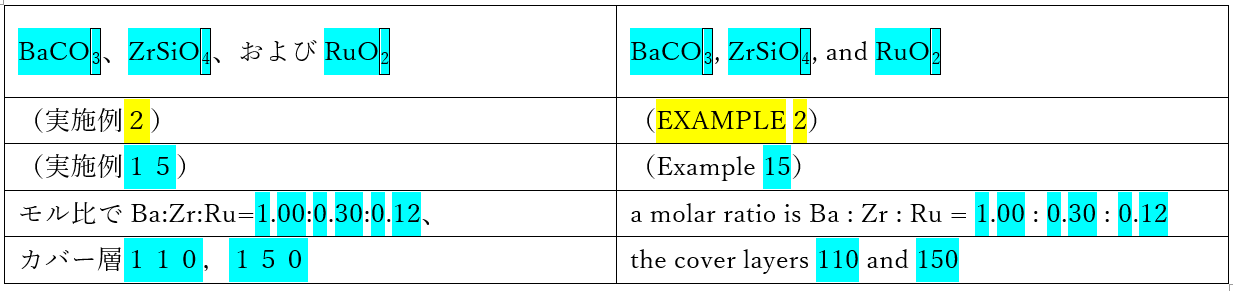
このような場合、チェック対象を数字とアルファベットと上付き・下付き文字とし、英文の2文字以上の大文字アルファベットもチェックすることになります。結果、以下のように着色されました。
![]()
そうです。英文中の大文字アルファベットの個所「EXAMPLE」が黄色になりました。和文中に対応する文字列がないからです。
チェックの狙い
この機能のチェック対象については、以下の2つの記事で紹介しています。
私はこの機能を、英文と和文とで同じ文字列を用いる場合を想定して作りました。よくある対象の文字列がが頭字語です。LEDやCPUなど、英文でも和文でも同じ言葉を用います。
ただ、今回のように英文中のアルファベットが和文で出ない場合には誤判定になってしまいます。
もしこのような誤判定が嫌いだったり、頭字語がそれほど使われていない文書の翻訳であれば、[英文の2文字以上の大文字アルファベットを和文でチェックする」をオフにしてください。
この項目を法務翻訳で使う場合にも注意が必要です。英文契約書の定義語も大文字で書かれます。
例:The SERVICE ...
この言葉は和文では「本サービス」となります。このように誤判定となる箇所が出てきますから、オフにしておいてよいと思います。
大文字の英文字3字以上が連なりそのあとに数字が続く場合、…
チェック結果
今度は別の設定項目です。[大文字の英文字3字以上が連なりそのあとに数字が続く場合、英文字と数字との間の半角スペースを無視する]のチェックも曲者です。分野によって使い分けましょう。
以下の設定でチェックしてみます。
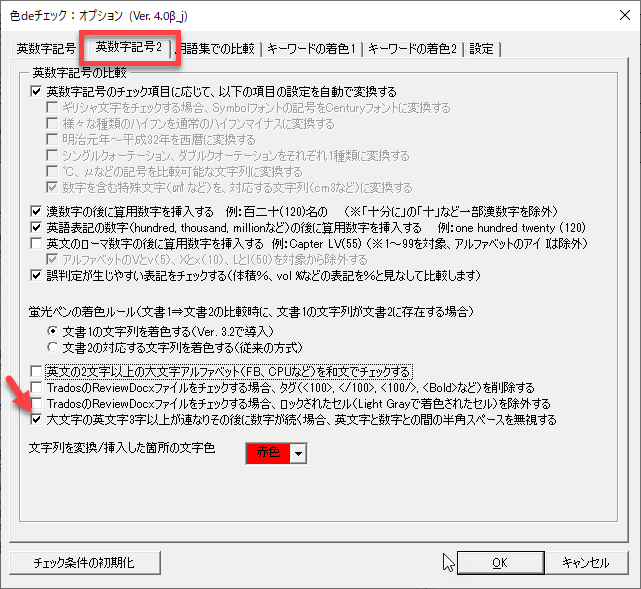
この場合、以下のようなチェック結果になります。
![]()
こちらもEXAMPLEに反応してしまいました。
チェックの狙い
この機能も具体的な事例に対処するために作りました。特許翻訳における頭字語と参照符号の誤判定を回避するためです。
[大文字の英文字3字以上が連なりそのあとに数字が続く場合、英文字と数字との間の半角スペースを無視する]がオフの場合、以下のようなチェック結果になります。
![]()
色deチェックでは、英文中のアルファベットは、数字と一体になっている場合に限りチェック対象になります。「100A」という記述の「A」はチェックされますが、ただ「A」と書かれていてもチェック対象にはなりません。
特許翻訳においては頭字語と参照符号が連続するため、上記のように誤判定がよく出ます。和文では頭字語と参照符号の間にスペースがありません。しかし、英文では半角スペースが必ず入っているため、頭字語と参照符号が別々の要素になってしまうのです。
その結果、和文の「CPU10」や「ROM10」が英文に見つからず、英文の「10」や「20」が和文で見つからないという事態になります。これが誤判定のメカニズムです。
そのため、特許翻訳の設定項目である[Patent Mech.]や[Patent Chem.]を選択した場合には、[大文字の英文字3字以上が連なりそのあとに数字が続く場合、英文字と数字との間の半角スペースを無視する]が自動的にオンになるように設定されています。また、[Customize]では任意に設定できるようになっています。

この設定の機能はその文言の通りです。具体的に言い換えると以下のようになります。
英文中にCPUやROMなどの3字以上の頭字語の直後に参照符号が続く場合、 頭字語と参照符号の間の半角スペースを無視する
ということです。
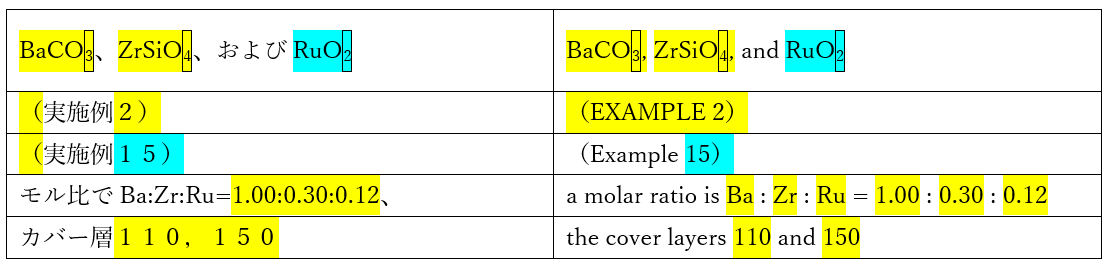
この設定がオンになったとき、チェック対象の英文は色deチェックにより以下のように解釈されます。
| CPU10はROM20に記録されているプログラムを実行する。 | The CPU10 executes the program stored in the ROM20. |
このようにすれば、和文と英文とでともに「CPU10」と「ROM20」が使われているので正しくチェックできるというわけです。
![]()
[英数字記号2]タブの設定を変更すると・・・
この記事で紹介したように上記2つをオフにしてチェックをしてみます。
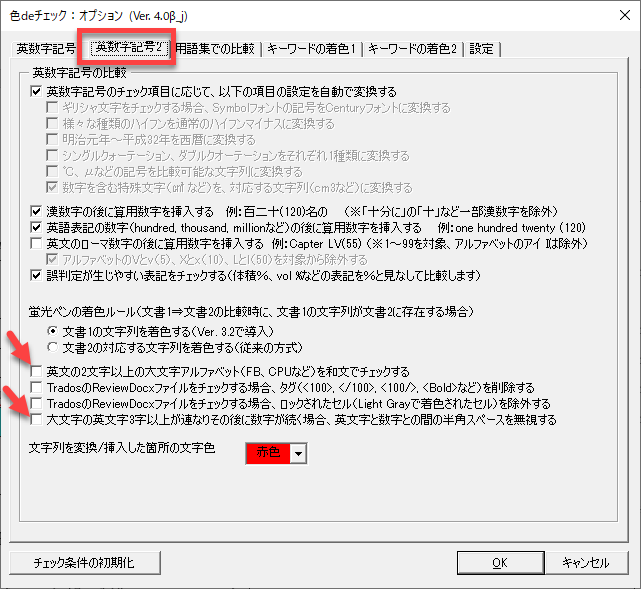
以下のように、EXAMPLEがチェック対象から外れて誤判定がなくなりました。

まとめ
今回の例では、「合っているのに黄色」(誤判定)がなくなるような設定方法を紹介しました。すべてを適用すれば以下のようになります。
実務では「合っているのに黄色」(誤判定)がなくすことは大切なのですが、完全にはなくなりません。
今回の記事と前回の記事でも繰り返し説明していますが、誤判定は必ず出てきます。機械的にチェックをしているだけだからです。
なので、みなさんがイライラしない程度の誤判定で抑えられるような設定を選んでみてください。
ちなみに私はこの記事で説明した2項目については基本的にはオンにしています。私が扱う特許文書や技術文書でのチェックの際にはこの2つの項目をオンにした方が誤判定が減るからです。
今回のようなEXAMPLE 1やEXAMPLE 2は誤判定になりますが、誤判定の理由がわかるのであまりイライラしません。
とは言ってもEXAMPLE 1やEXAMPLE 2など文中にたくさん表示される場合にはどうしたらいいのでしょうか。
どうしても気になる場合には、[検索と置換]ダイアログボックスの置換機能を使いましょう。以下のように[大文字と小文字を区別する]オプションをオンにした状態で置換をすると、大文字のEXAMPLEがすべて小文字のexampleに置換されます。
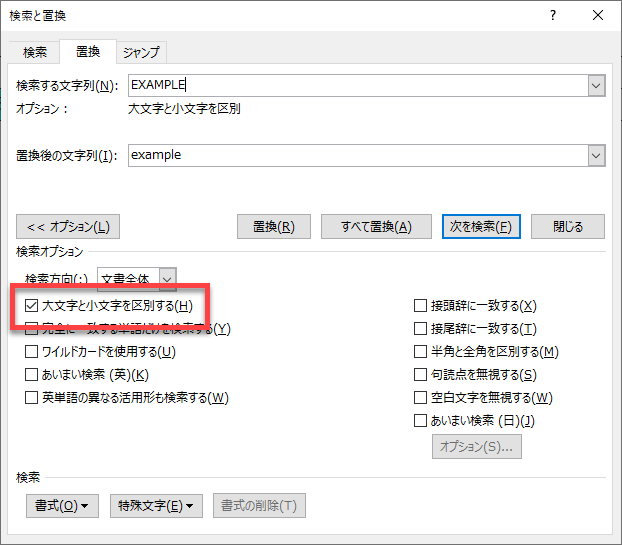
この置換によりチェック結果に不具合が出るかどうかは、文書全体をご存じのユーザーさんが一番よくわかりますよね。
各自で判断して一番いい設定をしてみてください。