






先日お客様から文字の頻度計算ができないかと問い合わせがありました。
用語集作りに役立つ「頻度のヒント」では、日本語や英語の単語を頻度順に抽出できますが、文字単位ではできません。
そこで作ってみました。
この点のマクロは、Wordの[検索と置換]ダイアログボックス(Findオブジェクト)を使うような頻度計算だと時間がかかりますので、すべて文字列として取り込んでそれを処理した方がいいです。
実際に「頻度のヒント」も同様の考え方で頻度計算をしています。
一般的なニーズがありそうだったら、この機能を頻度のヒントに組み込んでみようと思います。
<目次>
このマクロでできること
ワード文書の本文(メイン文書)に書かれている1文字ごとに使用頻度を計算します。
編集記号の頻度計算は除外していますが、若干残っています。あくまでもサンプルマクロなので適宜変更してご利用ください。
あと、VBScriptの正規表現(Wordのワイルドカードみたいなもの)で個数を数えています。
その関係で、マクロを簡単にするために、正規表現で使われるメタ文字(?や*などの記号)の個数は計算対象から除外しました。
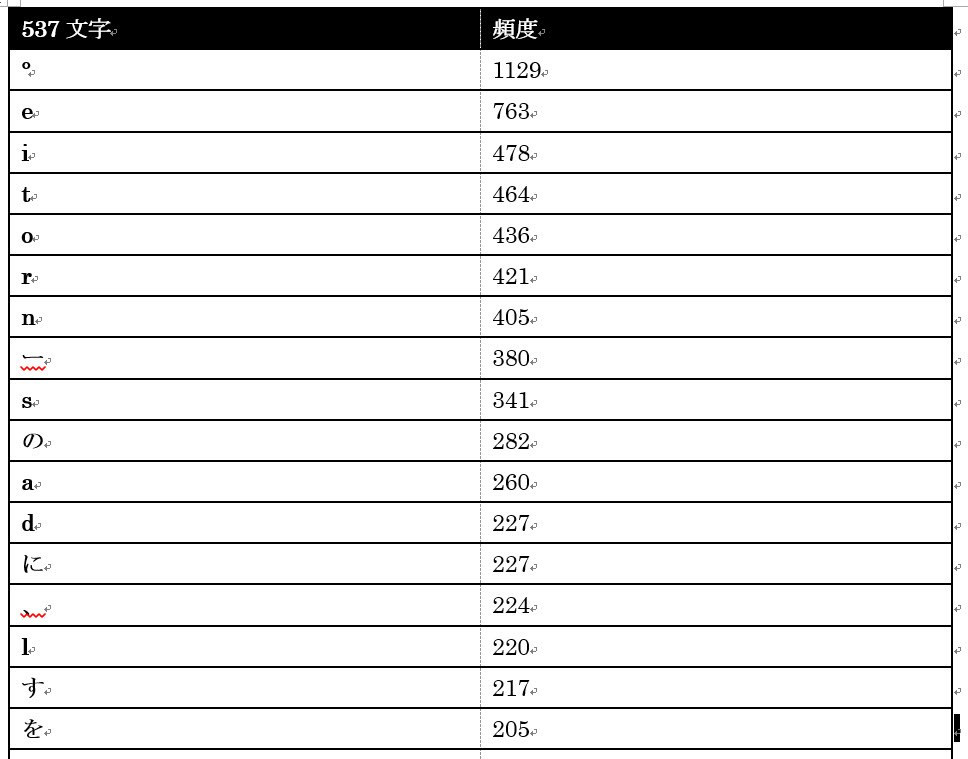
和文のサンプル
(実行前)

(実行後)
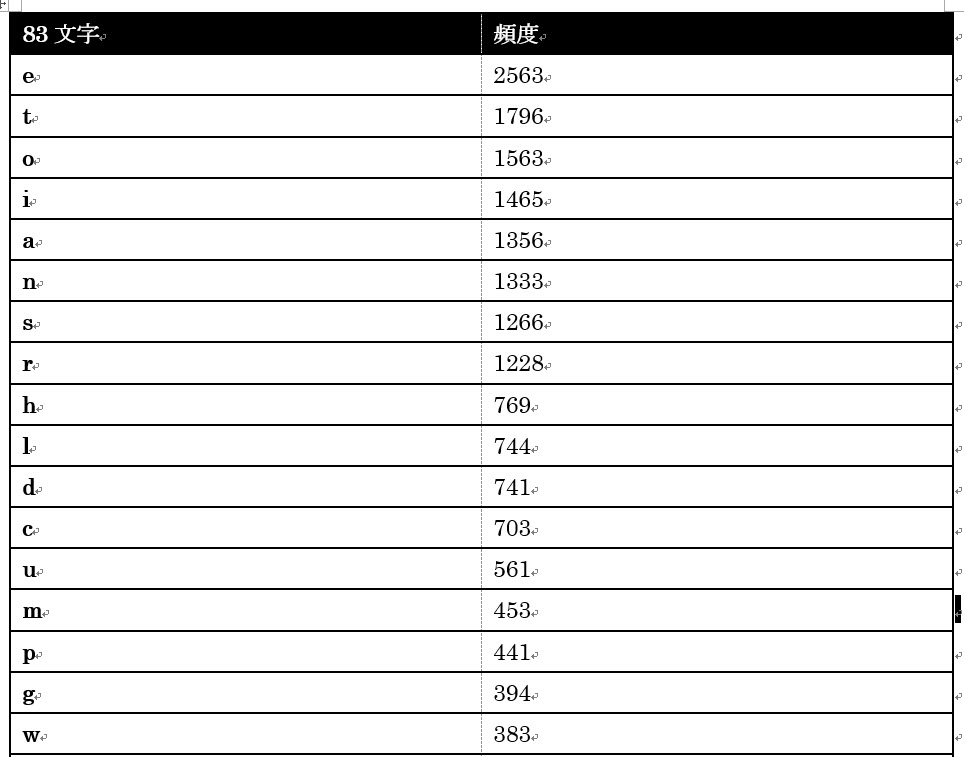
英文のサンプル
(実行前)

(実行後)
マクロの解説
VBAで正規表現をつかうには、RegExpオブジェクトを使います。
これを使うと、プログラム中で検索や置換などをWordのワイルドカードを使ったときのように自由にできます。また、検索のヒット件数も取得できますからけっこう便利です。
あと、Wordでも頻度順に並べ替えることできるんですよ!
Quick Sortなどプログラムを組み込んで並べ替える必要がないのでシンプルです。
まず、タブ区切りのデータ(文字と頻度のデータ)を表に変換します。(97行目)
そして、2列目の頻度の数字を基準にして降順に並べ替えるのです。(103行目)
マクロ
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 | Sub 文字の使用頻度() Dim myText As String Dim myFind As String Dim RE As Object Dim myMatch As Object Dim myResult As String Dim myExclude As String Dim myRange As Range Dim myDoc As Document Dim i As Long Dim myNG(6) As String '除外文字列(編集記号) '------------------------------------------- '初期設定 '------------------------------------------- myText = ActiveDocument.Content.Text DoEvents myResult = "文字" & vbTab & "頻度" myNG(1) = "\s" '空白文字、タブ文字 myNG(2) = "\v" '垂直タブ myNG(3) = "\t" '水平タブ myNG(4) = "\r" 'キャリッジリターン myNG(5) = "\f" '改ページ myNG(6) = "\n" '改行 '------------------------------------------- '除外文字列の削除 '------------------------------------------- Set RE = CreateObject("VBScript.RegExp") 'メタ文字の削除 myText = Replace(myText, ".", "") myText = Replace(myText, "?", "") myText = Replace(myText, "*", "") myText = Replace(myText, "+", "") myText = Replace(myText, "^", "") myText = Replace(myText, "\", "") myText = Replace(myText, "$", "") myText = Replace(myText, "|", "") myText = Replace(myText, "{", "") myText = Replace(myText, "}", "") myText = Replace(myText, "[", "") myText = Replace(myText, "]", "") myText = Replace(myText, "(", "") myText = Replace(myText, ")", "") DoEvents '除外文字列(編集記号)の削除 For i = 1 To 6 With RE .Pattern = myNG(i) ''検索する文字列 .IgnoreCase = True ''大文字と小文字を区別しない .Global = True ''文字列全体を検索 myText = .Replace(myText, "") ''置換後の文字列を空文字 End With DoEvents Next '------------------------------------------- '頻度計算 '------------------------------------------- Do While myText <> "" '1文字選択 myFind = Left(myText, 1) '選択した文字列の頻度計算 With RE .Pattern = myFind '検索する文字列 .IgnoreCase = False '大文字と小文字を区別する .Global = True '文字列全体を検索 Set myMatch = .Execute(myText) myResult = myResult & vbCr & myFind & vbTab & myMatch.Count DoEvents End With '選択した文字列を削除 myText = Replace(myText, myFind, "") DoEvents Loop '------------------------------------------- '結果表示 '------------------------------------------- If InStr(1, myResult, vbTab) Then Set myDoc = Documents.Add myDoc.Range.Text = myResult 'Rangeオブジェクトの取得 Set myRange = myDoc.Range '表の作成(タブ区切りを2列の表に変換) myRange.ConvertToTable Separator:=wdSeparateByTabs, _ NumColumns:=2, _ NumRows:=myDoc.Paragraphs.Count - 1 myRange.Tables(1).Style = wdStyleTableLightList '表の並べ替え(2列目の頻度の数字を降順) myRange.Tables(1).Sort ExcludeHeader:=True, _ FieldNumber:="列 2", _ SortFieldType:=wdSortFieldNumeric, _ SortOrder:=wdSortOrderDescending '文書先頭に抽出した文字数を挿入 myDoc.Paragraphs(1).Range.InsertBefore _ Text:=myDoc.Tables(1).Rows.Count - 1 End If '------------------------------------------- '後処理 '------------------------------------------- Set RE = Nothing Set myMatch = Nothing Set myRange = Nothing Set myDoc = Nothing End Sub |