






GreenTのGlossary Generator を使い、案件毎に用語集を作成します。この記事では、翻訳開始前に用語集を作成する方法を紹介します。
概要
これまでの翻訳と同様、原文の意味を理解した上で訳語を選択するわけなので、調べものにはある程度の時間がかかります。しかし、この調べものや用語の統一をツールを使って効率化をしているため、これまでの用語集作成よりは時間が短縮できると思います。
また、翻訳前に用語集を手堅く作るためには原文をある程度読み込まなければなりません。そのため、翻訳着手前に原文の内容をある程度頭に入れることができるので、後の翻訳作業のスピードアップにも欠かせない工程となります。
本記事で以下の項目を説明します。
翻訳開始前に用語集が必要ですか?
翻訳開始前には訳語を特定できないこともありますので、その場合には翻訳開始前に無理をして訳語登録をしなくてもよいと思います。この判断はこれまでの翻訳と同じです。翻訳をしながら用語登録をしたり編集したりする場合には以下の記事をご覧ください。
(参考:翻訳中に用語集を管理する方法)
また、用語集をチェック専用に使う方法も用意しています。用語集を訳文に自動で適用すると出力文がおかしくなることもあるからです。
(参考:出力された訳文の用語を修正する方法)
この挙動は分野や言語方向、登録する用語によって変わります。
みなさんが翻訳をしやすい方法を探してみてください。
用語集の作成手順
以下の2つの方法があります。
- 【基本編】手持ちの用語集(テキスト形式、Excel形式)を用いない場合
- 【応用編】手持ちの用語集を用いる場合(別の記事で紹介します)
いずれの場合も、ニューラル機械翻訳を活用して調べものをして裏をとりながら案件専用の用語集を作ります。完全に自動で用語集を作るわけではありません。
以下、【基本編】手持ちの用語集を用いない場合の説明をします。
1.用語の抽出
まず最初に原文ファイル内の用語(名詞句)を抽出します。機械的に抽出するため、名詞句ではないものが混ざりますので、適宜削除してください。
ツールバーの[GG]ボタンをクリックすると以下のダイアログボックスが表示されます。
まず、用語集に収める用語の出現頻度と複合語の単語の数を設定します。和文原稿の場合には、用語の文字数を設定します。
また、用語集を用いる場合には[オプション]ボタンをクリックして使用する用語集を登録しますが、ここでは用語集を用いない方法を紹介します。(頻度のみを使用して用語集を抽出します)
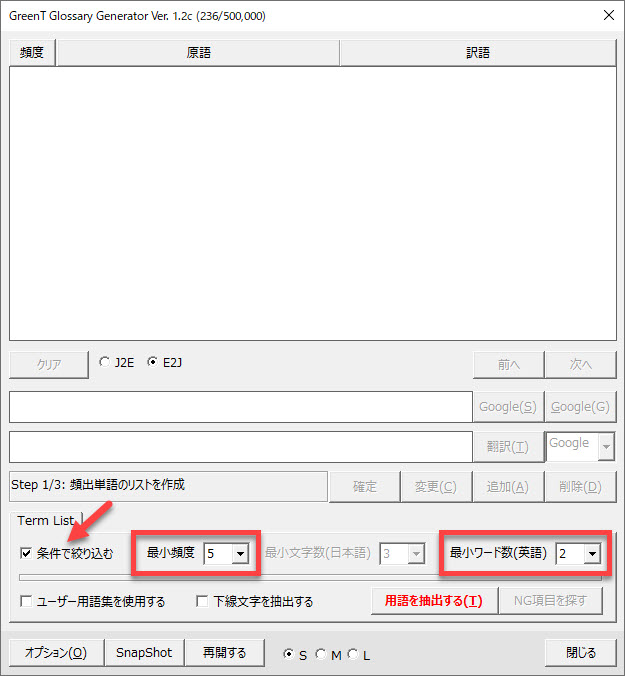
[用語を抽出する]ボタンをクリックすると条件に応じた用語が抽出されます。
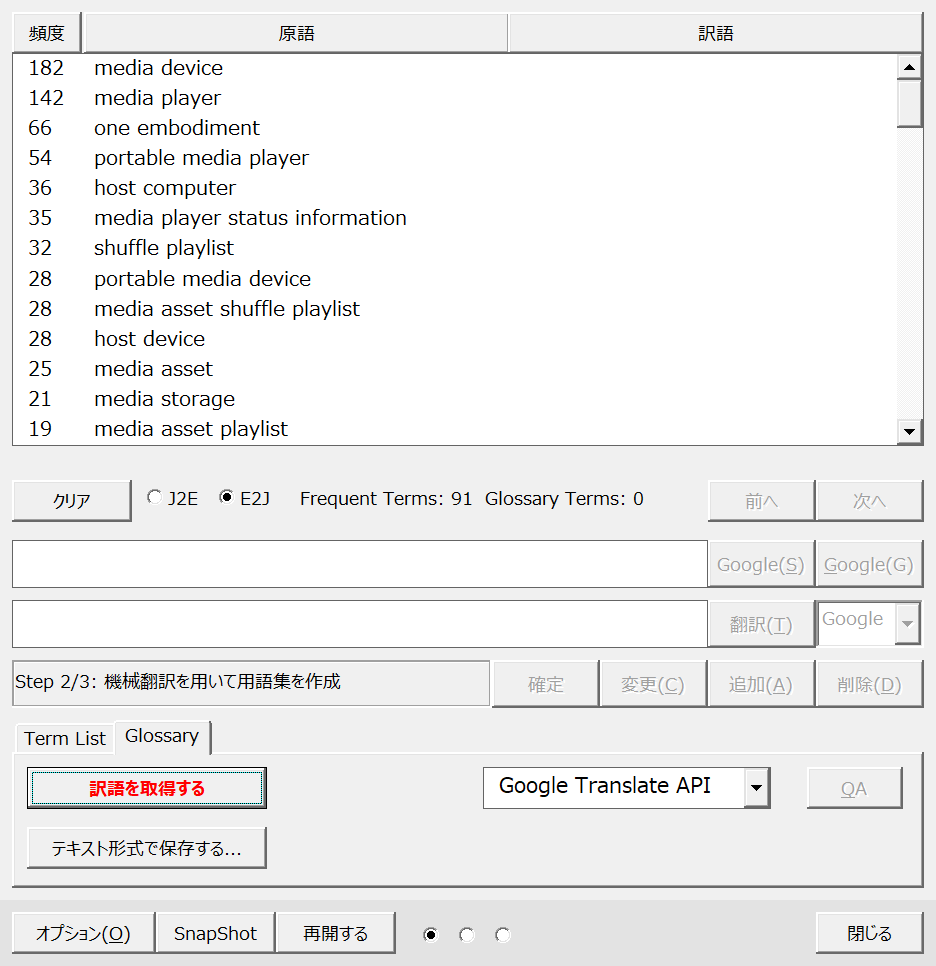
ここに抽出された用語は原文ファイル内での言葉の揺れがあるかもしれません。また、用語集にはふさわしくない言葉も含まれることもあります。そのため、[原語]ボタンをクリックして原語をABC順、あいうえお順にて並べ替えて言葉の揺れを確認します。

気になる言葉があればその言葉をクリックして[前へ]ボタンと[次へ]ボタンを使い原文ファイル内でどのような文脈で使われているのか確認します。
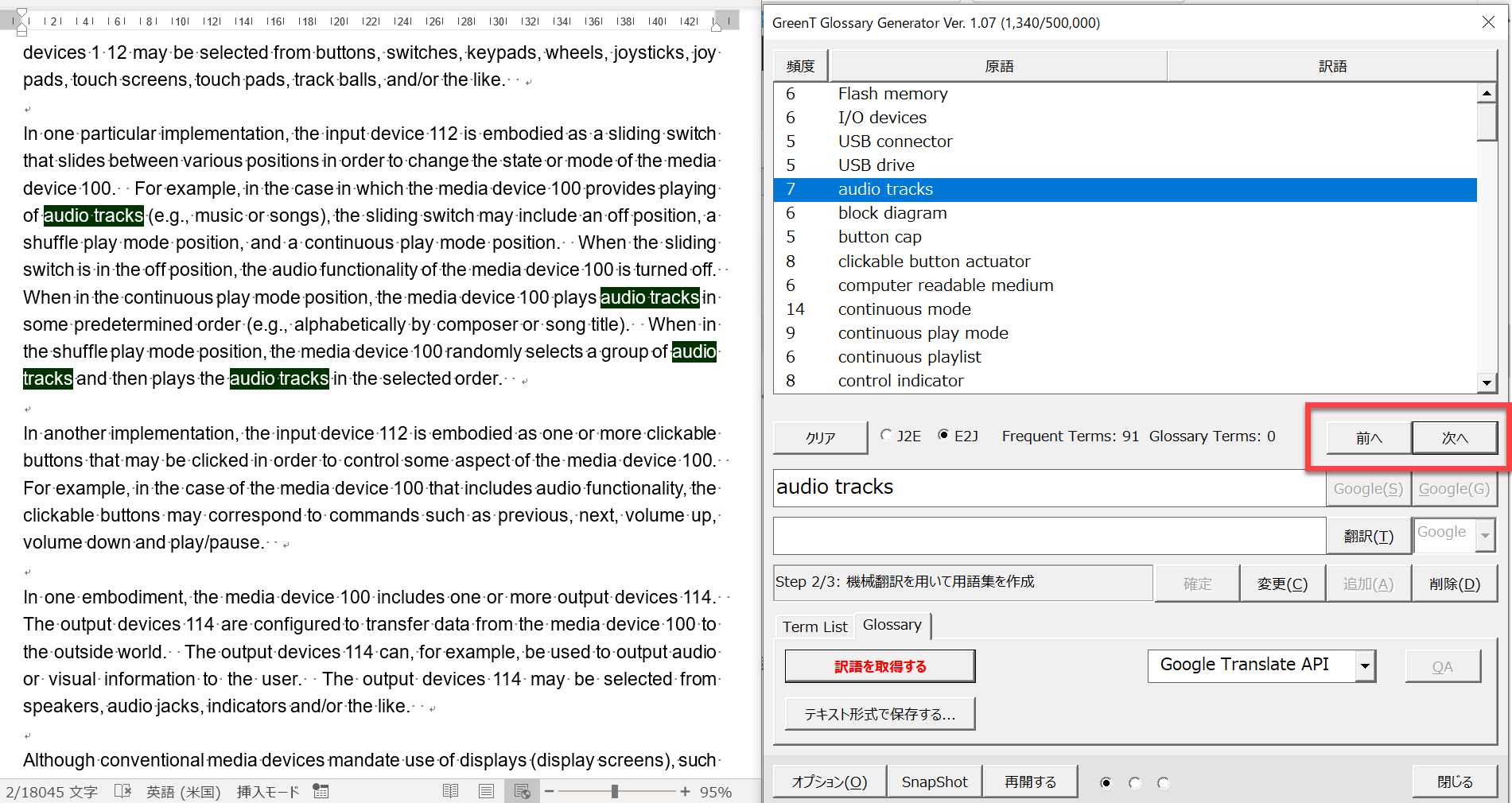
必要に応じて[削除]ボタンをクリックして抽出された言葉を削除してください。
2.訳語の作成
抽出した用語に対して訳語を作成します。①用語集を用いる場合には、用語集にある用語が優先的に用いられ、用語集にない訳語をニューラル機械翻訳で作成します。
以下、②の用語集を用いない場合の説明です。
[Glossary]タブの[訳語を取得する]ボタンをクリックします。すると、一覧にある用語1つ1つに対して指定したニューラル機械翻訳エンジンで訳語を生成します。
訳語が生成されると、自動的にQAチェックを実行します。QAチェックでは数字のチェックを実行し、原語と訳語とで相違がある場合に指摘をします。
以下のように原語の「first command」に対して訳語「最初のコマンド」が生成されており、これがQAチェックで指摘されました([QA]タブ)。原語の序数 first (1) に対応する数字が訳語にないということなのです。
原文を読むとクレーム中で first command, second command 、つまり「第1のコマンド」、「第2のコマンド」という文脈で使われている言葉だと分かりました。
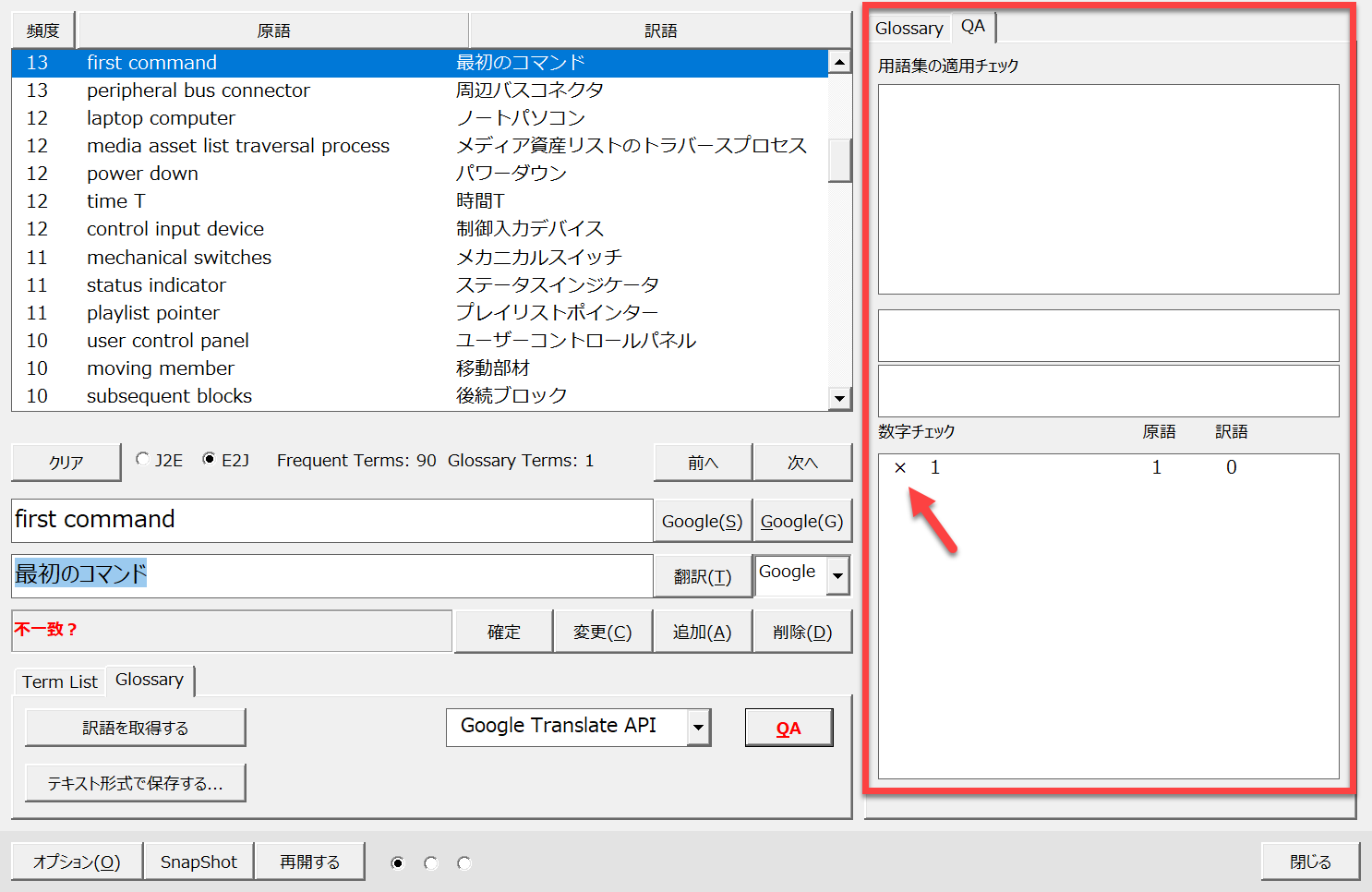
そこで、訳語の「最初のコマンド」を「第1のコマンド」に変更し[変更]ボタンをクリックします。すると、リスト内の表示が修正されて、メッセージが表示されます。
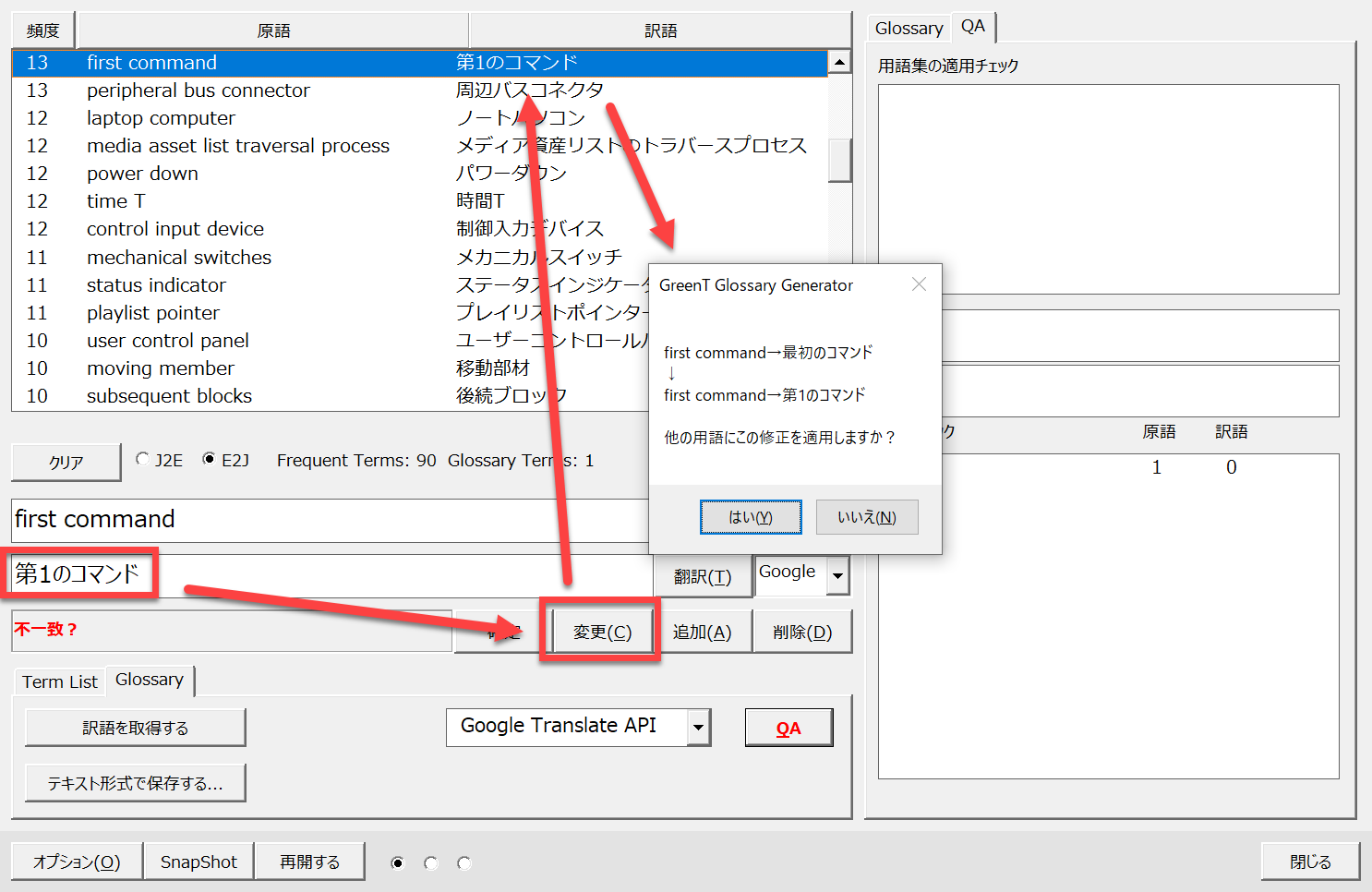
ここで[はい]ボタンをクリックすると、一覧にリストアップされたほかの用語でも同じ修正が適用されます。
つまり、仮に原語「first command generator」の訳語が「最初のコマンド生成部」となっている場合に、訳語が「第1のコマンド生成部」に自動的に修正されるということです。
このようにすることで用語集での訳語の統一が図られます。一斉に変更したくない場合には[いいえ]ボタンをクリックしてください。
また、ニューラル機械翻訳ではうまく用語が訳されない場合には、原語に言葉を補って機械翻訳をさせたり、辞書やネット検索や書籍から通常のように調べものをしてください。
上記ではQAチェックで指摘された箇所を修正しましたが、そのままの表記で正しい場合には[確定]ボタンをクリックしてください。ここで翻訳を確定すると、QAチェックで指摘されなくなります。
(参考:訳語の確定方法)
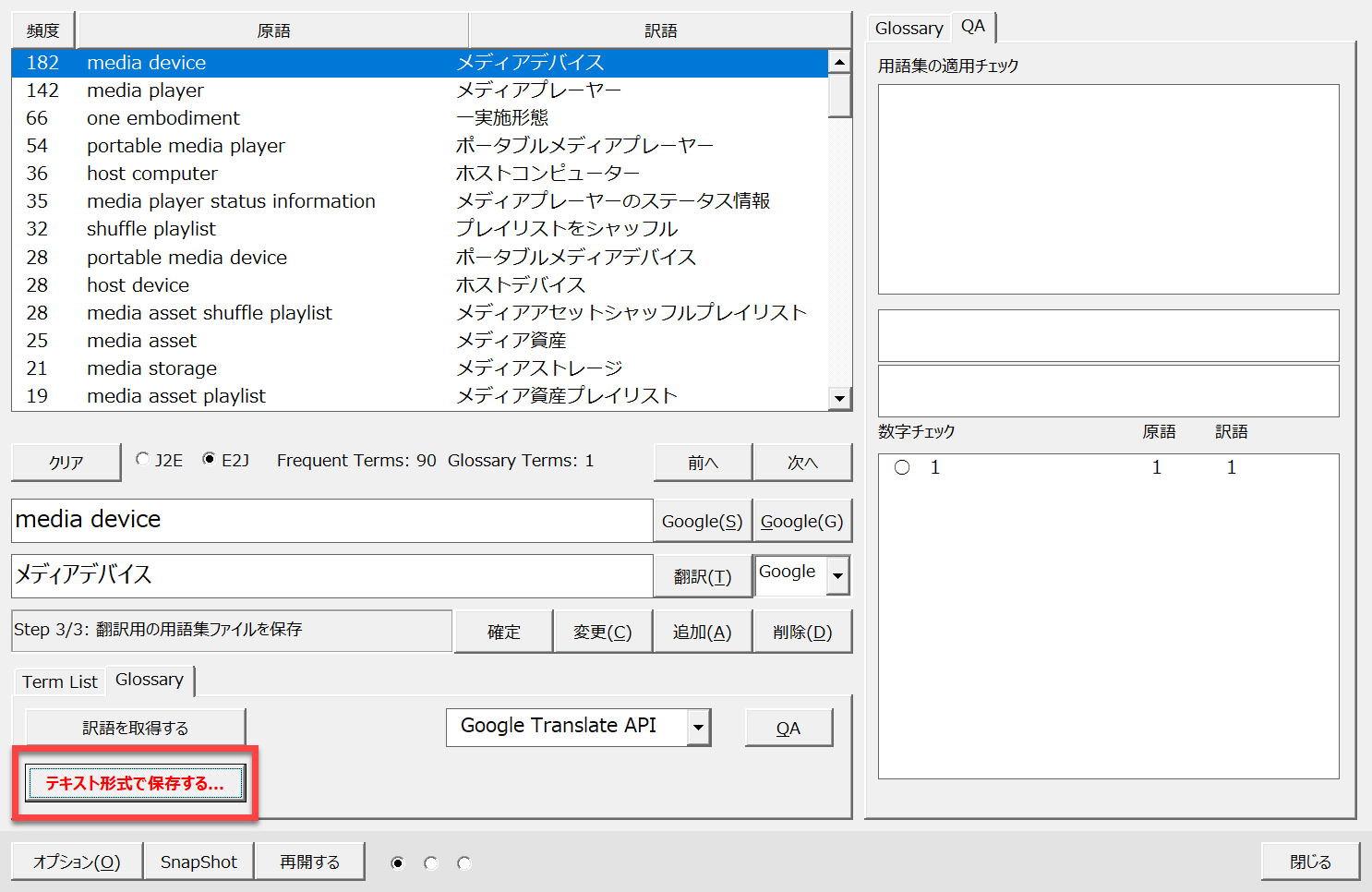
3.テキストファイルに保存
QAが全て終了したら、[テキスト形式で保存する]ボタンをクリックして用語集ファイルの保存先を選択して保存します。この用語集ファイルを翻訳時に利用するので、わかりやすい場所に保存してください。
用語集作成途中で保存し、後に作業を継続する方法
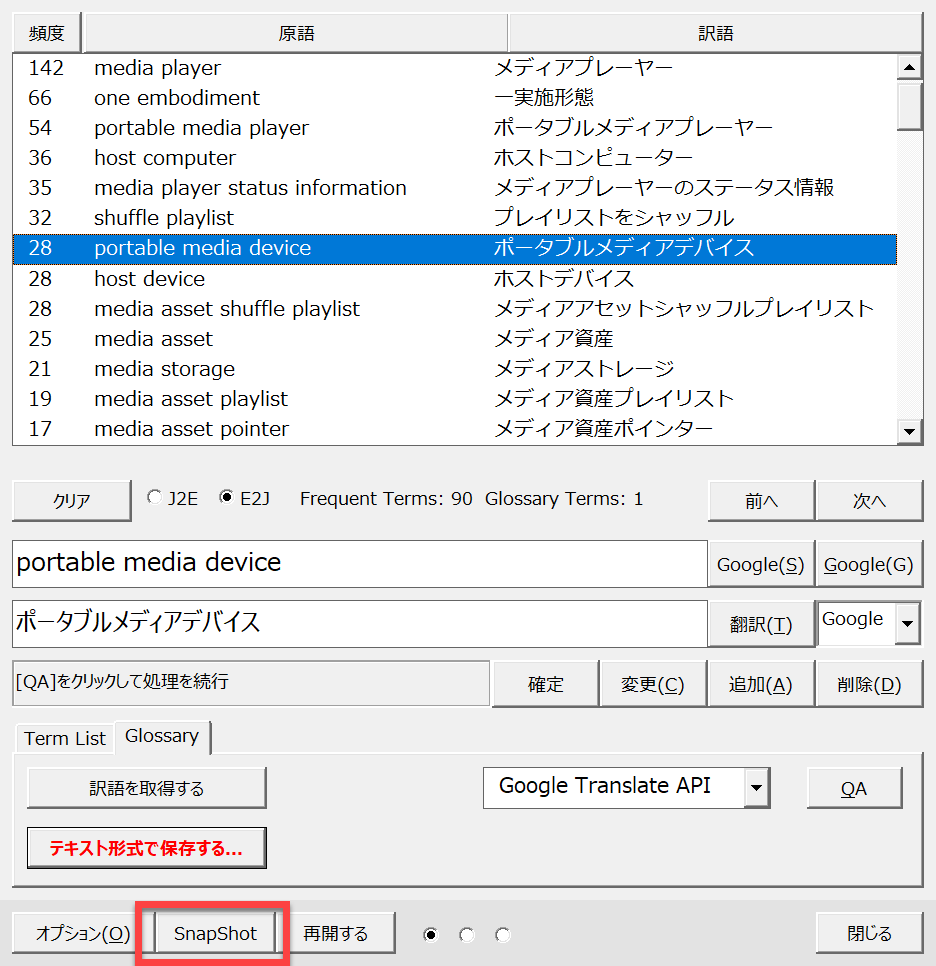
用語集の作成の途中で作業を一時停止できます。後日、同じ状態から作業を継続できます。
[Snapshot]ボタンをクリックすると、現在の作業状況をッ保存できます。
保存が完了するとメッセージが表示されます。
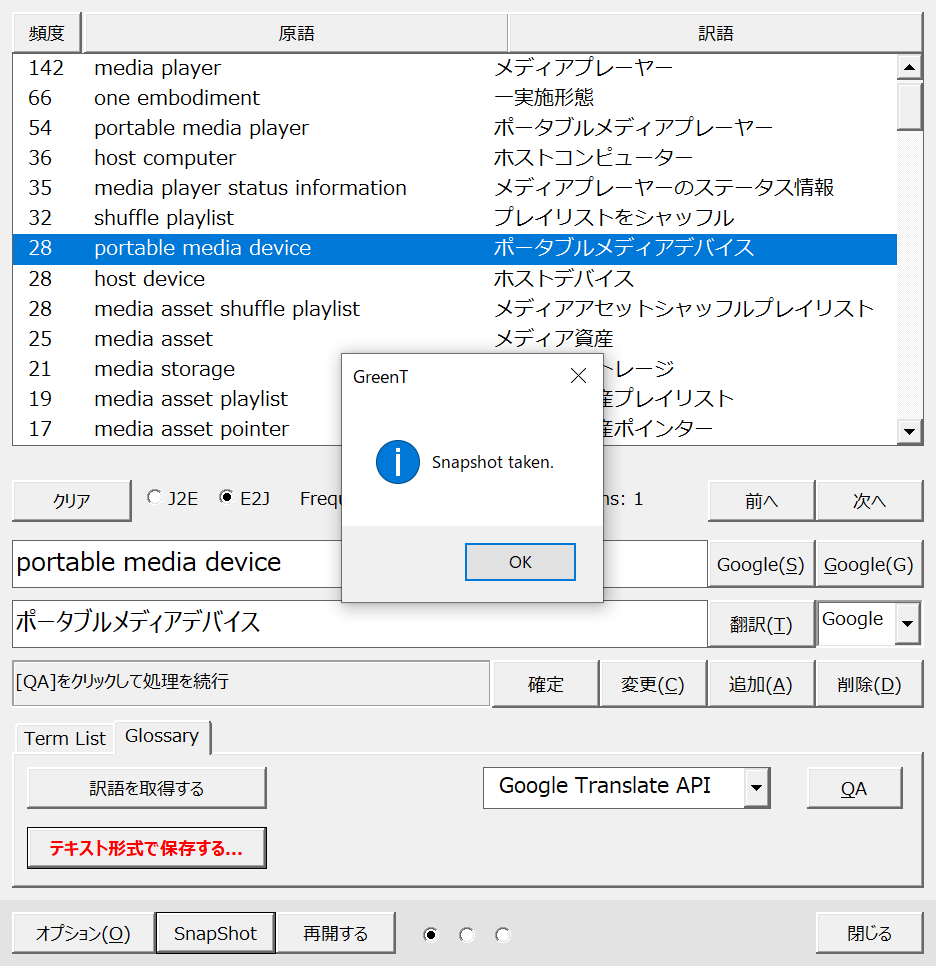
次に作業を開始するときには、アドインタブの[GG]ボタンからダイアログを立ち上げて[再開する]ボタンをクリックします。
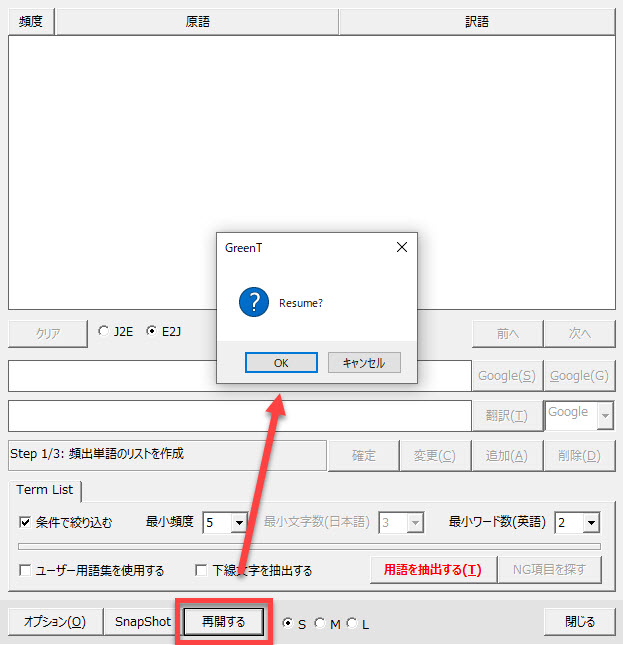
[OK]ボタンをクリックすると前回保存した状態が再現されます。一度呼び出すと元に戻せませんのでご注意ください。
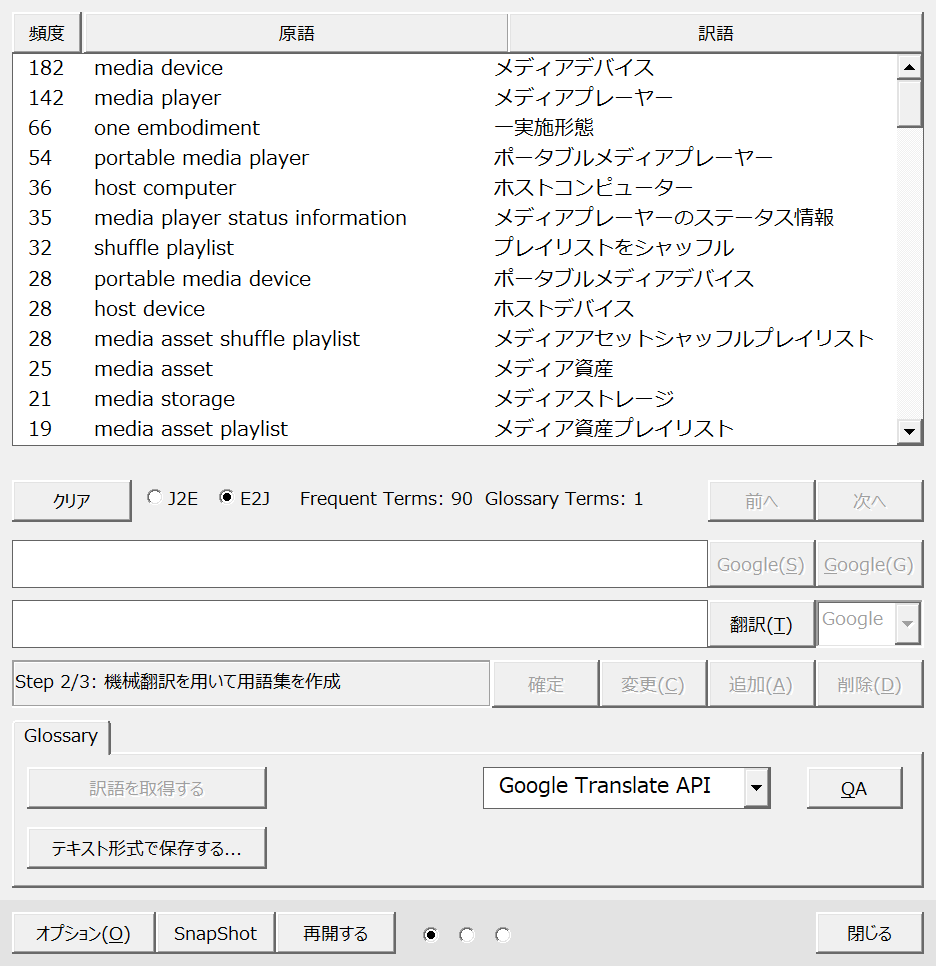
上記のように読み込まれました。訳語の確認作業を継続してください。
用語集ファイルの設定方法
作成した用語集おテキストファイルを翻訳で利用するために[GreenT]ダイアログで設定します。
[アドイン]タブの[GreenT]ボタンをクリックしてダイアログを開き、[Translate]タブの以下のボタンをクリックします。

用語集の設定画面が開きますので、赤枠の個所で今回作成したテキストファイルを登録します。
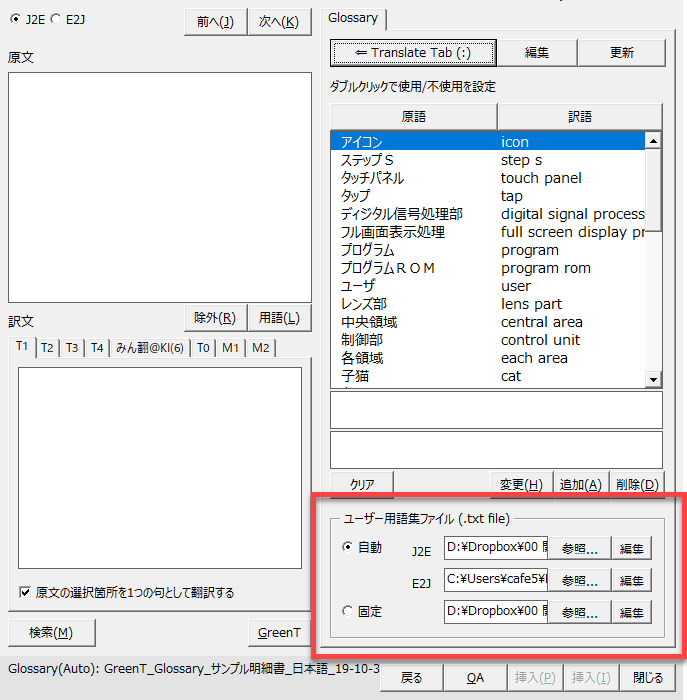
[自動]が選択されている場合、J2EとE2Jのファイルがダイアログ左上のラジオボタンと連動して翻訳言語方向に応じて自動的に切り替えられます。
- J2E:日英翻訳用
- E2J:英日翻訳用
[固定]が選択されている場合、翻訳言語方向に関わらず常に同じ用語集ファイルが使われます。
参考:訳文への用語集の適用
用語集作成の応用編
手持ちの用語集を用いる場合は、以下のページをご覧ください。
複数のファイルに共通した用語集も作成できます。