





機械翻訳では特定の表現や文字がある場合に誤訳を起こす可能性が高まります。
このような回避可能な誤訳であれば、原文を修正することで対処可能です。
GreenTには、誤訳しやすい文字・表現を自動修正するPre-Processing 機能があります。
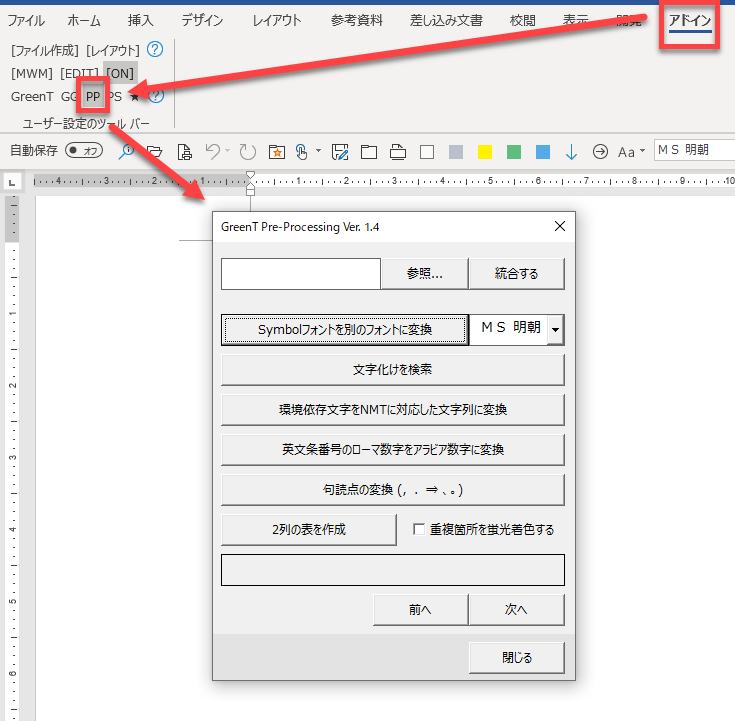
上記のように[Pre-Processing]ダイアログを開きます。
Wordファイルに対して処理をします。
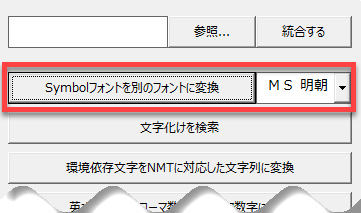
Symbolフォントの変換
Symbolフォントを指定した文字フォントに変換する機能です。
Web版のGoogle翻訳などの機械翻訳エンジンでは、Symbolフォントが使われていると誤訳の発生確率が高まるように感じます。
GreenTではそもそもSymbolフォントを読み込むことができません。

これを、たとえばMS明朝に書き換えると以下のように読み込めるようになります。変換箇所は黄色の蛍光ペンで着色されています。
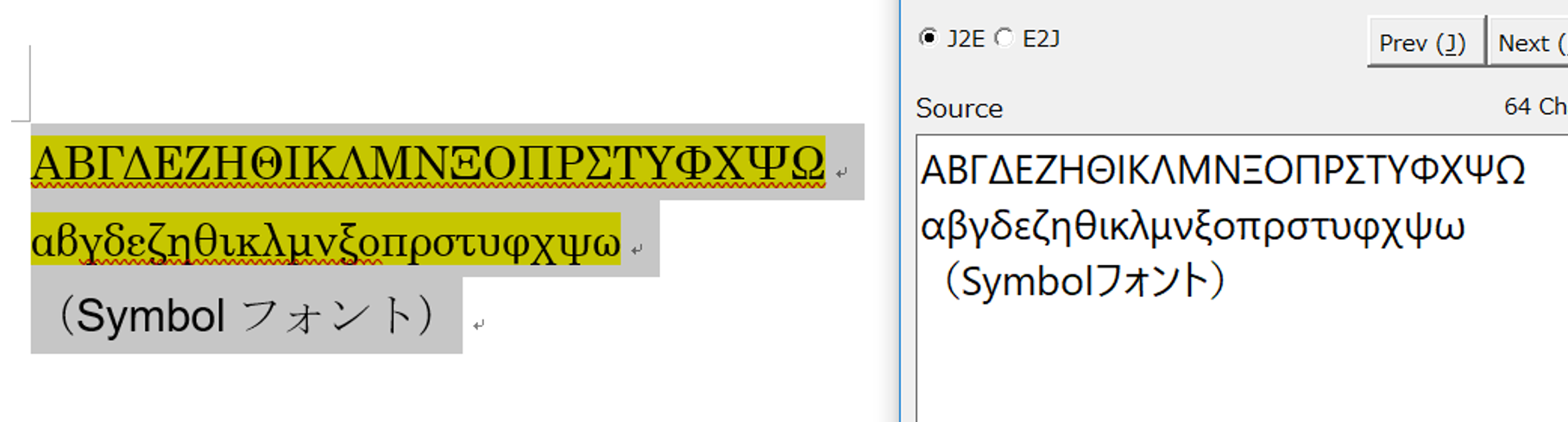
これであれば誤訳の可能性が低くなります。
文字化け箇所の検索
原文で文字化けをしている場合もあります。文字化け箇所があれば蛍光ペンで着色します。
環境依存文字の対処
特殊文字(例:㎜、㎝、㏠、㏡)を通常の文字列(mm、cm、1日、2日)に変換します。こうすれば翻訳もできますし、QAチェックもできます。
ローマ数字の対処
ローマ数字がけっこう曲者です。英文契約書に出てきますね。条番号として書かれているものに限り自動修正してアラビア数字にします。
以下のような場合に文中でも見出しでも条番号を変換します。

こんな感じで蛍光ペンで着色されます。
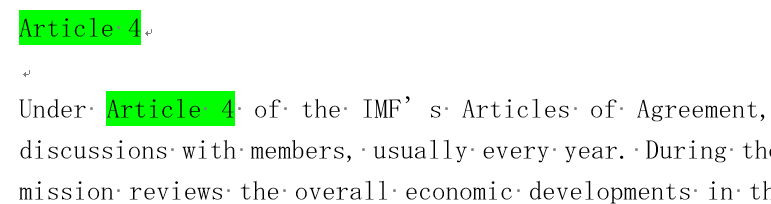
句読点の統一
論文で句読点を全角のピリオドとコンマ「.,」で書くことがあります。GreenTでは和文の文末の区切りを「。」の句点で特定しています。なので、原文の句読点を通常の「。、」に自動変換します。
かつて作成した以下のコードをブラッシュアップして使っています。
【コード】全角のコンマとピリオドを句読点に変換するWordマクロ(その2)
2列の表の作成
このダイアログには、内容把握のために2列の表を作成する[2列の表を作成]ボタンがあります。
使い方については、以下のページをご覧ください。