






GreenTにはテキストメモリ機能があり、過去の翻訳テキスト内の文字列を検索できます。
デフォルトでは、日英翻訳用に「GreenT_TextMemory_J2E.txt」、英日翻訳用に「GreenT_TextMemory_E2J.txt」のテキストメモリが用意されています。
別のテキストメモリを使う場合があると思います。この機能で使用されるテキストメモリの作り方を説明します。
ファイルの仕様
Unicode形式(UTF-16)のテキストファイル
原文と訳文をタブ区切りで入力
ファイルの作成方法
原文を先頭に入力し、その次にタブ記号を入力、そして訳文を入力します。
これで1つのセグメントとなります。訳文の後に改行を入力します。
次のセグメントを入力します。これを繰り返して1段落にタブで区切られた原文と訳文が入力されています。

Excelで原文と訳文のセグメントを管理している場合には、隣り合う列に原文と訳文を用意し、それをメモ帳にコピペするだけでタブ区切りのファイルを用意できます。
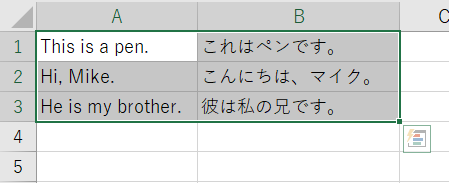
用意したテキストファイルをUnicode形式で保存します。
保存方法については、以下のページをご覧ください。