



色deチェックでは、チェック対象の言語が2バイト文字なのか1バイト文字なのかを3つの方法で判定できます。言語の種類を正確に判定しないと、正確なチェック結果が得られません。それぞれ特徴があるので用途に応じて使い分けてください。
<目次>
設定方法
チェックの[オプション」ダイアログボックスの[設定]タブの以下のボタンで設定します。
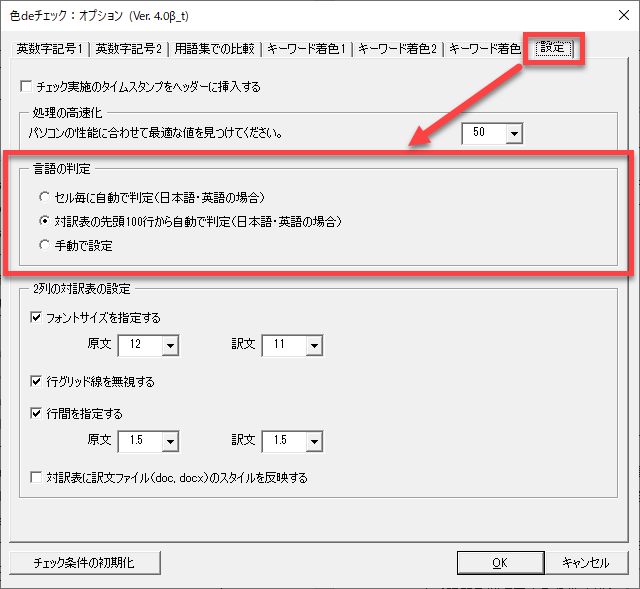
以下の3つの方法があります。それぞれについて説明します。
- セルごとに自動で判定
- 対訳表の先頭100行から自動で判定(Ver. 4.0以降のデフォルト)
- 手動で設定
セルごとに自動で判定
Ver. 3.7d以前の自動判定の方法です。原文セルと訳文セルの文字列の種類をチェックするたびに判定します。日本語と英語のみ判定できます。
そのため、以下のように原文と訳文の言語方向が異なる場合でも正確にチェック結果を表示できます。和文と判定された文中のアルファベットをチェックしますが、英文中のアルファベットはチェック対象外ですよね。
(チェック結果)

ところが、以下のように和文中にアルファベットが多く書かれる場合には、和文ではなく英文であると誤判定をしてしまい、正確にチェックできません。本当は、URLに間違いがあるのですが、訳文が英文と判定されているためアルファベットをチェック対象外としてしまっているのです。
(チェック結果)

対訳表の先頭100行から自動で判定
Ver. 4.0以降で利用できる判定方法です。原文と訳文の言語を対訳表の先頭から最大で100行分の文字列から総合的に判定をします。日本語と英語のみ判定できます。
判定された言語は以下の個所に表示されます。
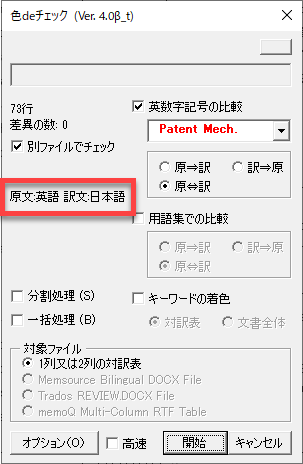
原文と訳文の言語を正確に判定できれば訳文の列は和文であると判定されるため、以下のようなチェック結果になり誤訳個所を特定できます。
(チェック結果)

ただし、以下のように対訳表の先頭の文字列からは原文と訳文の言語を正確に判断できない場合には誤判定が起こります。
原文は英語、訳文は日本語の場合なのですが、先頭から100行目までの文字列に日本語がほとんど含まれないため、訳文が英語と誤判定されてしまっています。そのため、英文中と判定された訳文中のアルファベットはチェック対象外となり、赤矢印で示した誤訳個所を検出できませんでした。
(チェック結果)

手動で設定
3つ目の方法では原文と訳文の言語を手動で設定します。こうすれば、自動判定による誤判定を回避できます。
「手動で設定」を選択した場合には、チェックダイアログに以下のように2バイト文字と1バイト文字の選択用のラジオボタンが表示されます。ラジオボタンが表示されていない場合には、右上のボタンをクリックして詳細表示にしてください。
このラジオボタンで原文と訳文の言語を選択してください。今回の例では、英日翻訳なので原文を1バイト文字、訳文を2バイト文字に設定します。
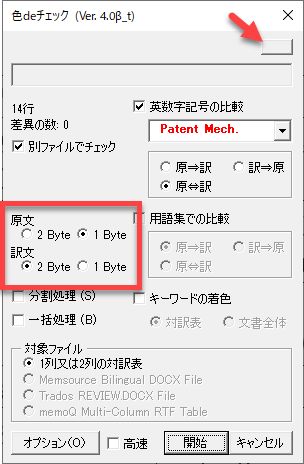
すると、以下のように誤訳個所を正確に検出できます。

なお、自動判定機能では、英語と日本語の場合だけ原文と訳文の言語を判定できます。そのため、タイ語など日本語以外の言語では1バイト文字と誤判定をしてしまいます。
このような場合にも手動で設定をしてください。
(参考:2バイト文字の言語をチェックする設定方法)